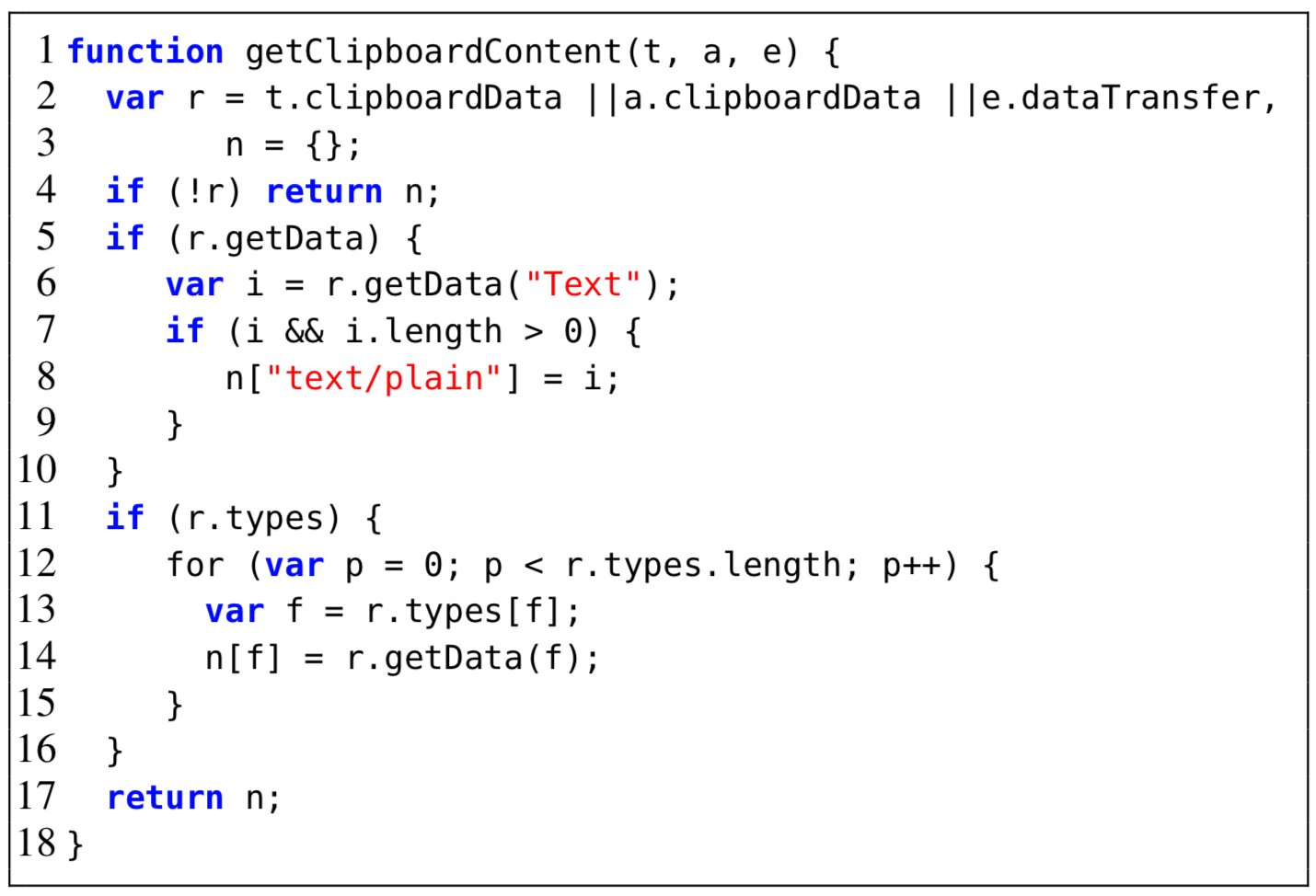
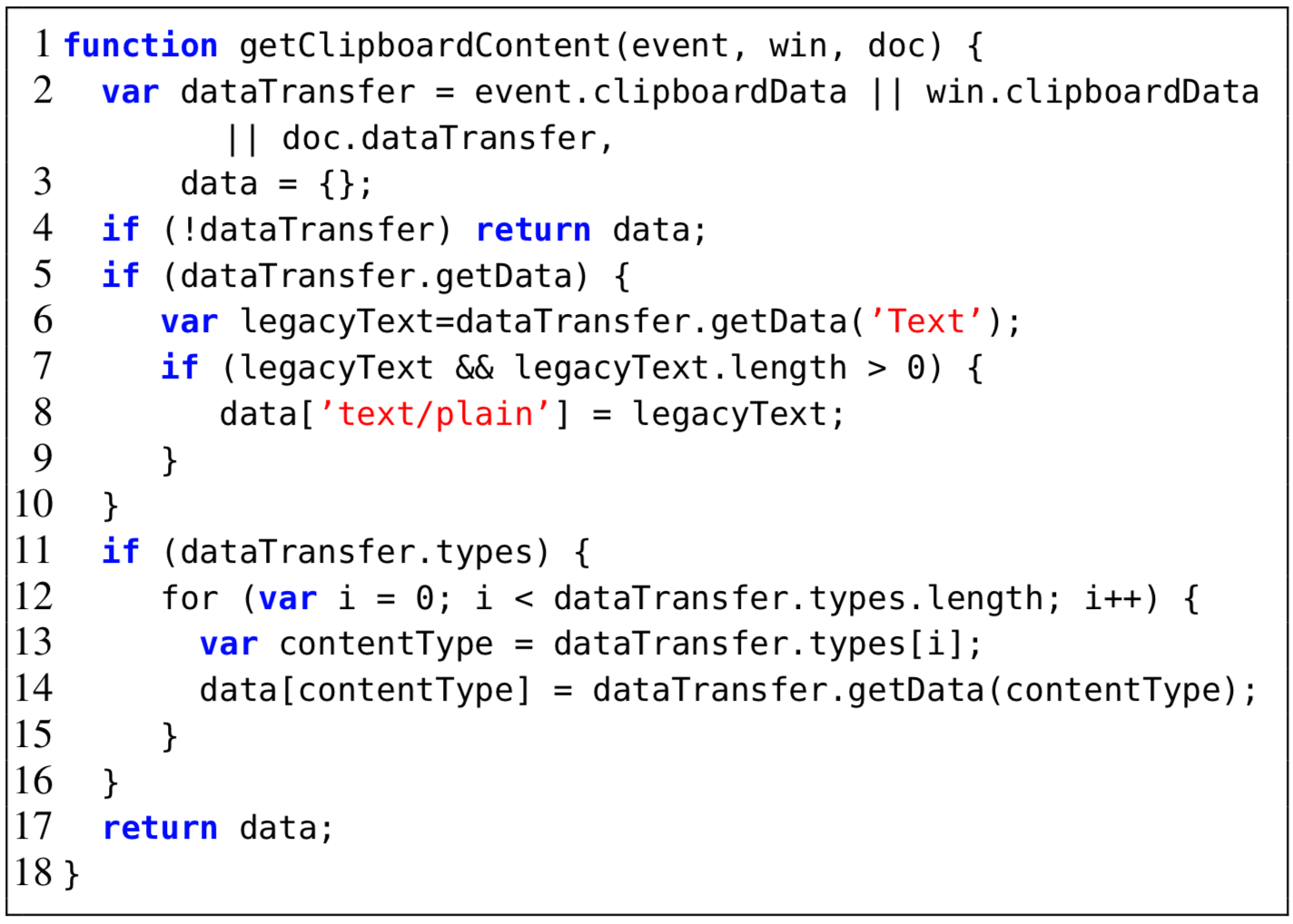
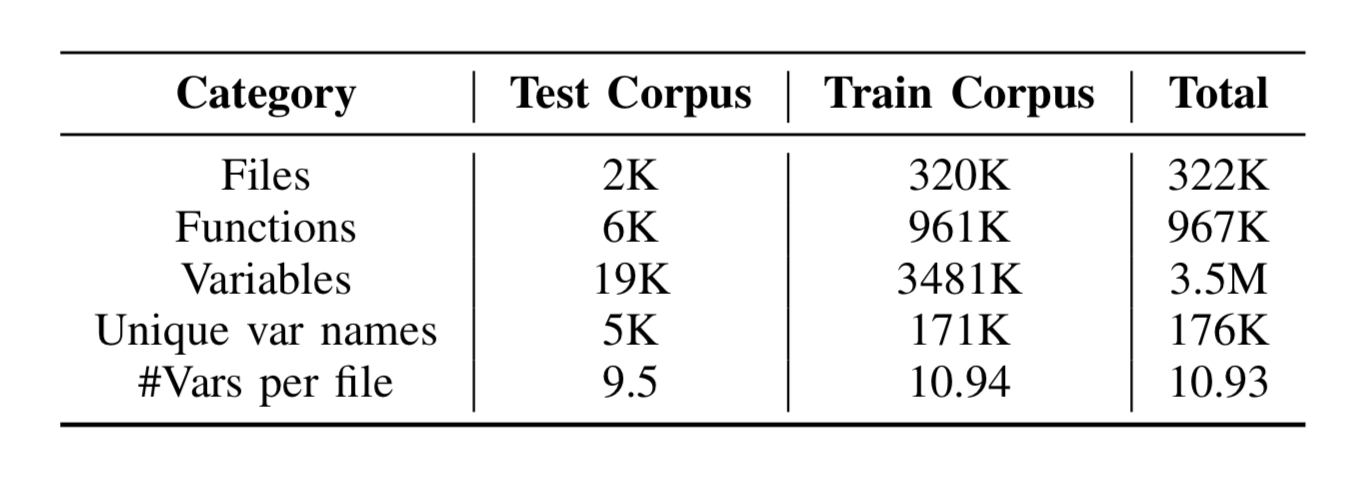
To study different factors that have impact on JSNEAT’s accuracy, in our entire dataset, we randomly chose one fold for testing and the remaining 9 folds for training. We studied the following factors: relation graph size, type of relation edges, thresholds, beam widths, pair or triple associations, different weight parameters, and data size.

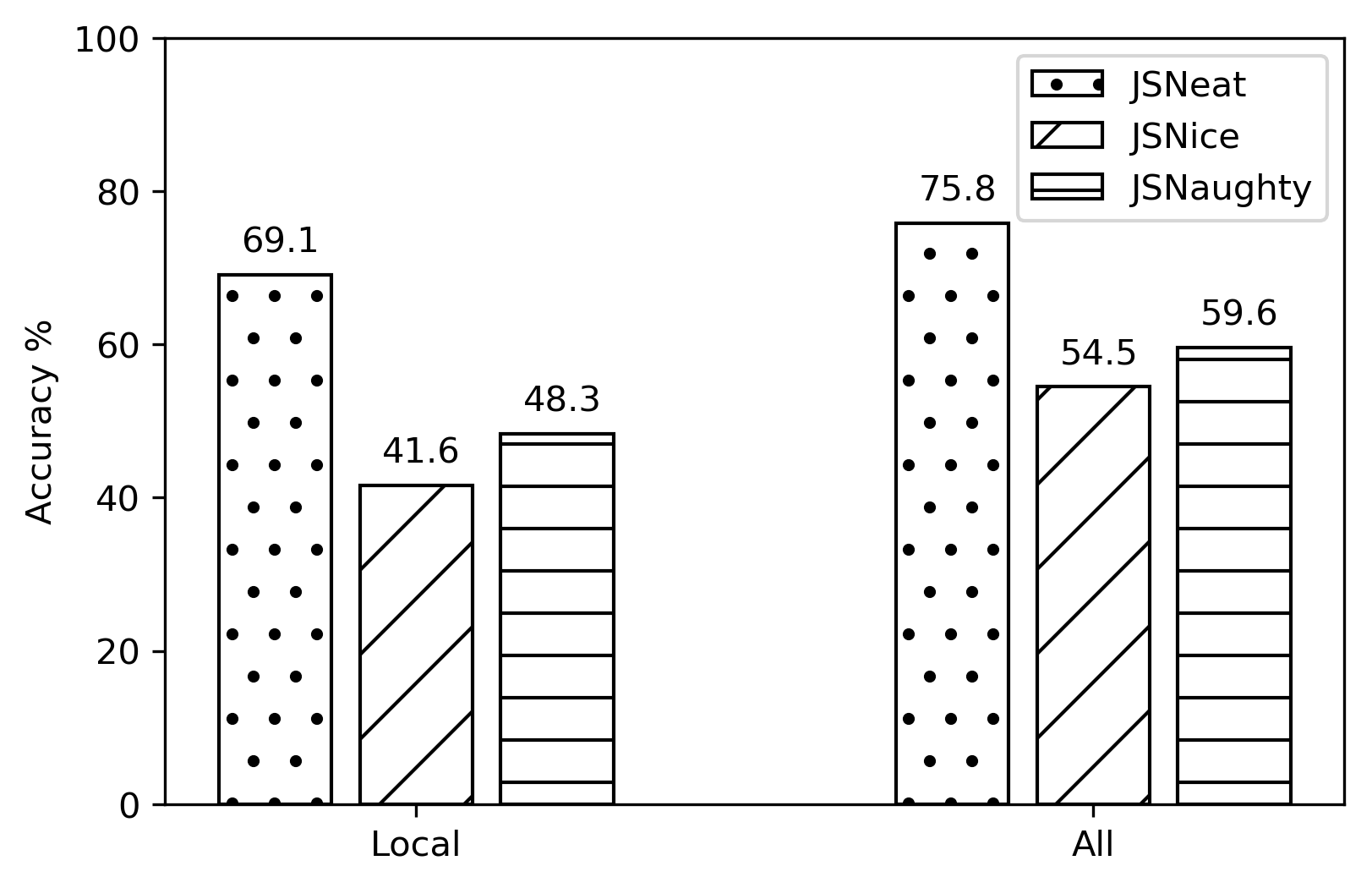
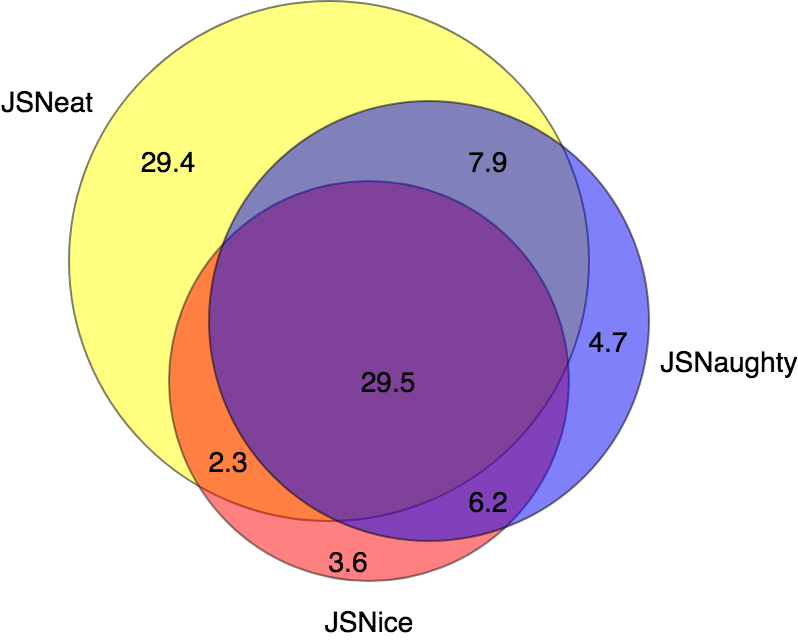
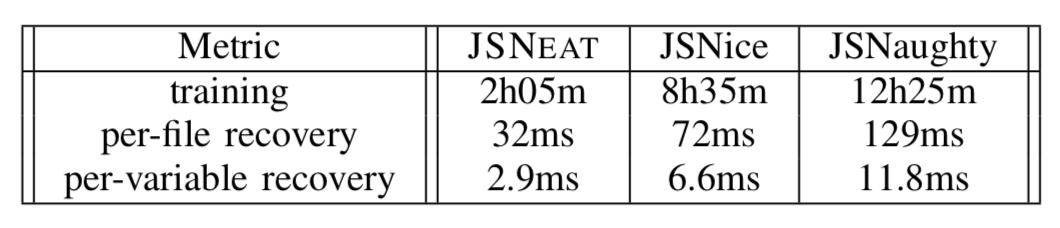
10-fold Cross Validation Evaluation for JSNEAT

Accuracy by Relation Graphs’ Sizes
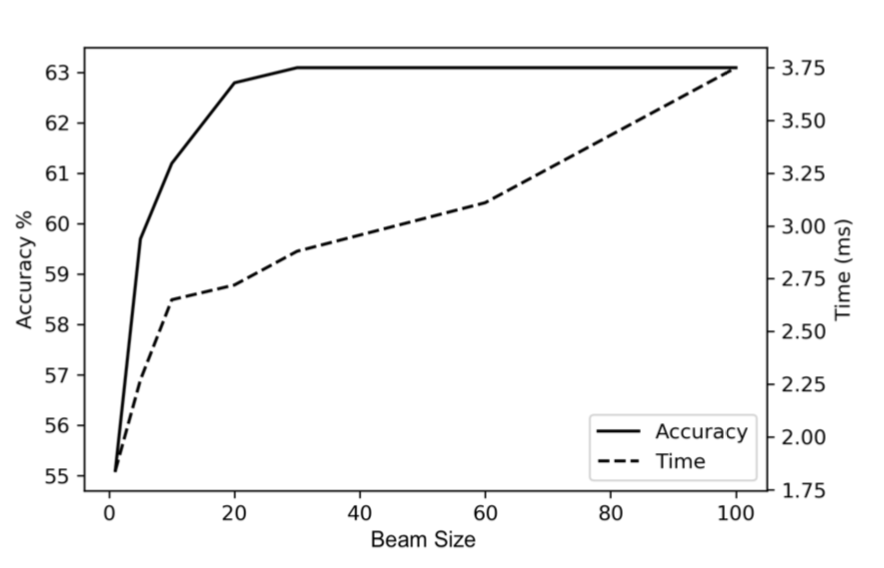
Impact of Beam Size on Accuracy and Running Time

Impact of Training Data’s Size on Accuracy
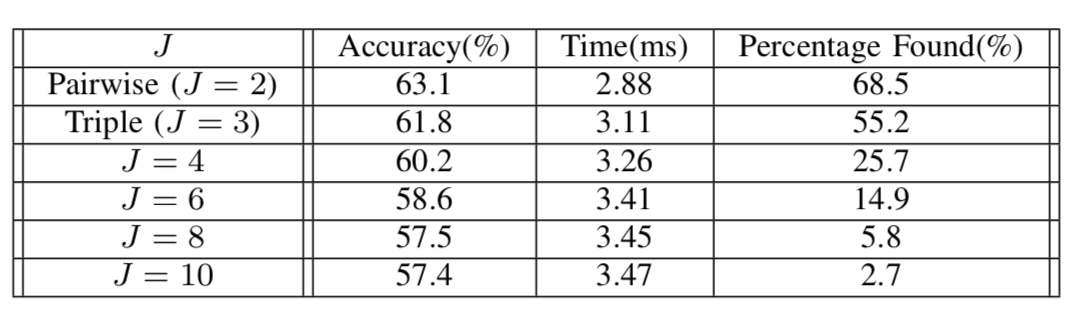
Impact of Assoc Score J on Accuracy and Time
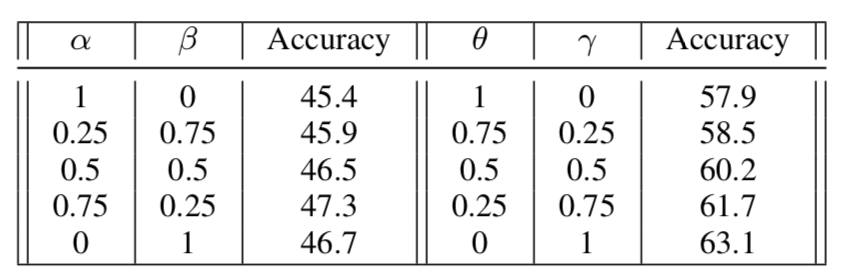
Sensitivity Analysis on Combination Parameters

Impact of Threshold φ on Accuracy

Impact of Relation Types in RGs to Accuracy